Datasets from Library of Congress
Datasets from the Library of Congress include all outputs from the Connections in Sound project. The following is a description of these resources, which can be found at www.github.com/rootseire/LC-ITM
AFC Sankey
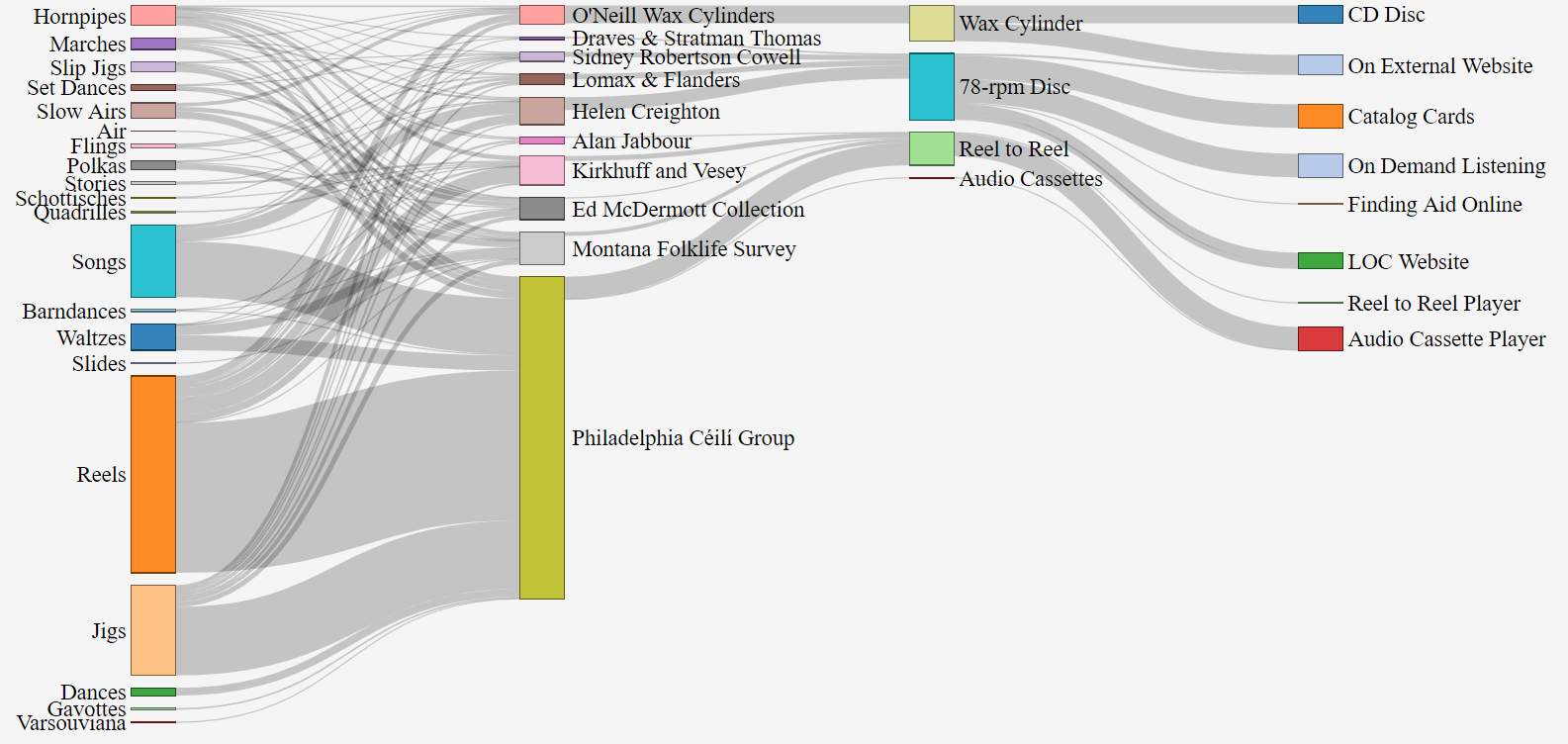
Sankey visualisation of audio recordings from the American Folklife Center at the Library of Congress
Dataset originally created 03/01/2019 UPDATE: Packaged on 04/18/2019 UPDATE: Edited README on 04/18/2019
I. About this Data Set This data set is a snapshot of work that is ongoing as a collaboration between Kluge Fellow in Digital Studies, Patrick Egan and an intern at the Library of Congress in the American Folklife Center. It contains a combination of metadata from various collections that contain audio recordings of Irish traditional music. The development of this dataset is iterative, and it integrates visualizations that follow the key principles of trust and approachability. The project, entitled, “Connections In Sound” invites you to use and re-use this data.
The text available in the Items dataset is generated from multiple collections of audio material that were discovered at the American Folklife Center. Each instance of a performance was listed and “sets” or medleys of tunes or songs were split into distinct instances in order to allow machines to read each title separately (whilst still noting that they were part of a group of tunes). The work of the intern was then reviewed before publication, and cross-referenced with the tune index at www.irishtune.info. The Items dataset consists of just over 1000 rows, with new data being added daily in a separate file.
The collections dataset contains at least 37 rows of collections that were located by a reference librarian at the American Folklife Center. This search was complemented by searches of the collections by the scholar both on the internet at https://catalog.loc.gov and by using card catalogs.
Updates to these datasets will be announced and published as the project progresses.
II. What’s included? This data set includes:
- data-april-2019.zip – zip file containing 2 .CSV files and a README file
- items – a .CSV containing Media Note, OriginalFormat, On Website, Collection Ref, Missing In Duplication, Collection, Outside Link, Performer, Solo/multiple, Sub-item, type of tune, Tune, Position, Location, State, Date, Notes/Composer, Potential Linked Data, Instrument, Additional Notes, Tune Cleanup. This .CSV is the direct export of the Items Google Spreadsheet
- collections – a .CSV containing Viewed?, On LOC?, On other website?, Original Format, On Website, Search, Collection, State, Other states, Era / Date, Call Number, Finding Aid Online?, Tune Names?, Tune Details, Quantity of Recordings
III. How Was It Created? These data were created by a Kluge Fellow in Digital Studies and an intern on this program over the course of three months. By listening, transcribing, reviewing, and tagging audio recordings, these scholars improve access and connect sounds in the American Folklife Collections by focusing on Irish traditional music. Once transcribed and tagged, information in these datasets is reviewed before publication.
IV. Data Set Field Descriptions
IV
a) Collections dataset field descriptions
- ItemId – this is the identifier for the collection that was found at the AFC
- Viewed – if the collection has been viewed, or accessed in any way by the researchers.
- On LOC – whether or not there are audio recordings of this collection available on the Library of Congress website.
- On Other Website – if any of the recordings in this collection are available elsewhere on the internet
- Original Format – the format that was used during the creation of the recordings that were found within each collection
- Search – this indicates the type of search that was performed in order that resulted in locating recordings and collections within the AFC
- Collection – the official title for the collection as noted on the Library of Congress website
- State – The primary state where recordings from the collection were located
- Other States – The secondary states where recordings from the collection were located
- Era / Date – The decade or year associated with each collection
- Call Number – This is the official reference number that is used to locate the collections, both in the urls used on the Library website, and in the reference search for catalog cards (catalog cards can be searched at this address: https://memory.loc.gov/diglib/ihas/html/afccards/afccards-home.html)
- Finding Aid Online? – Whether or not a finding aid is available for this collection on the internet
b) Items dataset field descriptions
- id – the specific identification of the instance of a tune, song or dance within the dataset
- Media Note – Any information that is included with the original format, such as identification, name of physical item, additional metadata written on the physical item
- Original Format – The physical format that was used when recording each specific performance. Note: this field is used in order to calculate the number of physical items that were created in each collection such as 32 wax cylinders.
- On Webste? – Whether or not each instance of a performance is available on the Library of Congress website
- Collection Ref – The official reference number of the collection
- Missing In Duplication – This column marks if parts of some recordings had been made available on other websites, but not all of the recordings were included in duplication (see recordings from Philadelphia Céilí Group on Villanova University website)
- Collection – The official title of the collection given by the American Folklife Center
- Outside Link – If recordings are available on other websites externally
- Performer – The name of the contributor(s)
- Solo/multiple – This field is used to calculate the amount of solo performers vs group performers in each collection
- Sub-item – In some cases, physical recordings contained extra details, the sub-item column was used to denote these details
- Type of item – This column describes each individual item type, as noted by performers and collectors
- Item – The item title, as noted by performers and collectors. If an item was not described, it was entered as “unidentified”
- Position – The position on the recording (in some cases during playback, audio cassette player counter markers were used)
- Location – Local address of the recording
- State – The state where the recording was made
- Date – The date that the recording was made
- Notes/Composer – The stated composer or source of the item recorded
- Potential Linked Data – If items may be linked to other recordings or data, this column was used to provide examples of potential relationships between them
- Instrument – The instrument(s) that was used during the performance
- Additional Notes – Notes about the process of capturing, transcribing and tagging recordings (for researcher and intern collaboration purposes)
- Tune Cleanup – This column was used to tidy each item so that it could be read by machines, but also so that spelling mistakes from the Item column could be corrected, and as an aid to preserving iterations of the editing process
V. Rights statement The text in this data set was created by the researcher and intern and can be used in many different ways under creative commons with attribution. All contributions to Connections In Sound are released into the public domain as they are created. Anyone is free to use and re-use this data set in any way they want, provided reference is given to the creators of these datasets.
VI. Creator and Contributor Information
Creator: Connections In Sound
Contributors: Library of Congress Labs
VII. Contact Information Please direct all questions and comments to Patrick Egan via www.twitter.com/mrpatrickegan or via his website at www.patrickegan.org. You can also get in touch with the Library of Congress Labs team via LC-Labs@loc.gov.
Leave a Reply